
Data Contamination in MLE-bench
How to test language models for prior exposure with Kaggle competitions

Last month, OpenAI released MLE-bench, a novel benchmark for evaluating machine learning agents on machine learning engineering tasks. The idea behind the benchmark is quite nice: The agent (usually a composite system involving an LLM) has to solve Kaggle competitions, similar to how humans would compete on Kaggle. This is illustrated in the following figure from the MLE-bench paper:
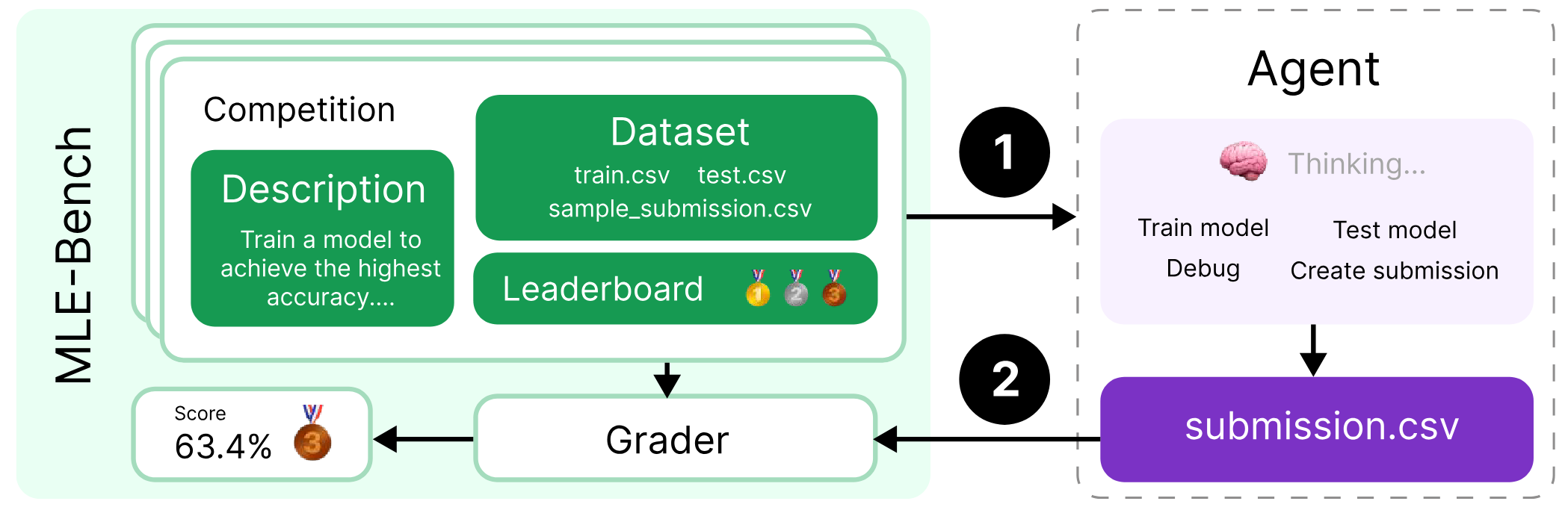
Kaggle competitions are publicly available, and some of the competitions in MLE-bench have been on the Internet for years. This raises the question: How valid are performance evaluations on this benchmark for LLMs that have seen the competitions during training?
Many of the competitions in MLE-bench include tabular datasets (the “train.csv” file in the figure above). Incidentally, I spent quite some time thinking about data contamination with tabular datasets, leading to this recent COLM paper. We also published the tabmemcheck software package, which can automatically test LLMs for contamination with tabular data. So when MLE-bench came out, I was naturally curious how much GPT-4o was contaminated with the datasets in the benchmark.
In this blog post, I want to show how we can test GPT-4o for prior exposure with Kaggle competitions (via their tabular datasets). To illustrate the relevance of this, I will consider competitions that are part of MLE-bench (Spoiler alert: We will see that there is contamination).
Before we begin, I want to clarify that I think OpenAI is doing a pretty good job dealing with contamination in their paper—much better than what we usually see in the literature. The purpose of this post is to complement their analysis and show how some of the datasets in the benchmark are more contaminated than others. At the end of the post, I will comment on the interplay between contamination and evaluation.
The code to reproduce the results in this blog is in this Jupyter Notebook.
Primer: Kaggle Titanic is Memorized in GPT-4o
Let us begin by discussing Kaggle Titanic as an example of a highly memorized dataset. In the MLE-bench paper, the authors note that
“GPT-4’s base model could reproduce several rows from the dataset of the “Titanic - Machine Learning from Disaster" competition when given the first few rows as a prompt.”
We don’t need access to the base model to see this. Instead, we can instruct GPT-4o with few-shot examples to respond with the content of a tabular dataset:
User: sepal_length,sepal_width,petal_length,petal_width,species5.1,3.5,1.4,0.2,Iris-setosa4.9,3,1.4,0.2,Iris-setosa4.7,3.2,1.3,0.2,Iris-setosa4.6,3.1,1.5,0.2,Iris-se
Assistant: tosa5,3.6,1.4,0.2,Iris-setosa5.4,3.9,1.7,0.4,Iris-setosa4.6,3.4,1.4,0.3,Iris-setosa5,3.4,1.5,0.2,Iris-setosa4.4,2.9,1.4,0.2,Iris-setosa4.9,3.1
We now use this prompt template to condition the GPT-4o to respond with the initial rows of the dataset we are interested in.1 We call this test the header test. Performing this test with our Python package is as simple as follows.
header_test(“kaggle-titanic.csv”, “gpt-4o-2024-08-06“)
By colouring the text, we visualize the Levenshtein string distance between the model response and the actual content in the dataset (additionally, the prompt is depicted as standard text). In this example, the model response is fully green, meaning GPT-4o responds with the next 15 rows of the Kaggle Titanic dataset without a single mistake.
Naturally, we can extend the memorization analysis from the initial rows to the entire dataset. We ask the LLM to complete randomly chosen rows, which we call the row completion test.
row_completion_test(“kaggle-titanic.csv”, “gpt-4o-2024-08-06“, num_queries=10)
The model completed 7 out of 10 rows correctly, filling in the names and many unique digits (the entirely green rows). For 3 other rows, the model did not quite get the content of the dataset right: The mistaken and missing parts are coloured in red and violet, respectively. Overall, however, we see that GPT-4o has memorized almost the entire Kaggle Titanic dataset.
As it turns out, many of the highly popular tabular datasets (think UCI Machine Learning repository) are memorized in GPT-4. For further details, see our COLM paper.
MLE-bench Datasets are not Memorized Verbatim
Are the competitions in MLE-bench memorized in the same way as the Titanic dataset? To assess this, we can use the header and row completion tests. MLE-bench is quite large, so for this blog, I consider a subset of 18 MLE-bench competitions that come with relatively unique CSV files.2
For the New York City Taxi Fare Prediction problem, the initial rows of the dataset are verbatim memorized.
header_test(“new york city taxi fare.csv”, “gpt-4o-2024-08-06“)
The interpretation of the coloured text is the same as before - in this example, the LLM response diverges from the dataset content after three rows.
For the other 17 datasets that I tested, the header test did not indicate memorization. Instead, the model responses looked more like this:
header_test(“SIIM-ISIC Melanoma Classification.csv”, “gpt-4o-2024-08-06“)
This is actually a nice example of GPT-4o being a powerful predictor without any evidence for memorization.
I also ran the row completion test for all 18 datasets, asking GPT-4o to complete 25 rows each.
row_completion_test(“Tabular Playground Series May 2022.csv”, “gpt-4o-2024-08-06“)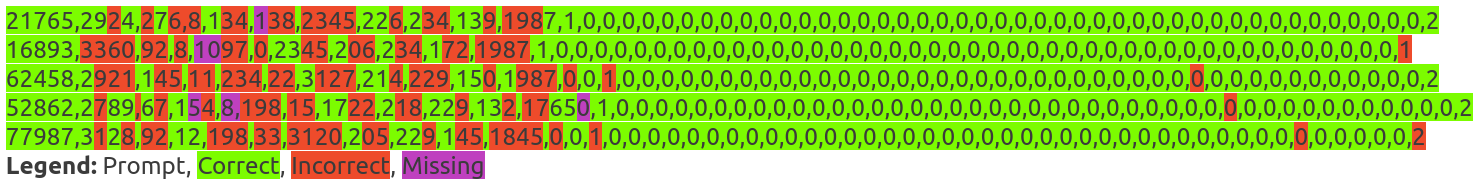
Again, the row completion test did not indicate memorization for any of the datasets in MLE-bench.3
In conclusion, there is little evidence that GPT-4o has memorized the datasets in MLE-bench verbatim, meaning that it has probably not stored the ground-truth labels of different dataset instances within its parametric knowledge.
MLE-bench Datasets are Still Contaminated
Of course, verbatim memorization of the training data is only the most extreme form of contamination.4 GPT-4o could still have seen ample information about the Kaggle competitions in MLE-bench during pre-training without starting to memorize entire text sequences. We are now going to conduct a number of tests which will reveal that this is the case.
GPT-4o knows the feature names of MLE-bench datasets
As a simple measure of how much the LLM knows about a dataset, we ask the LLM to list the names of the features in the dataset. Like in the memorization tests, we instruct the model with few-shot learning to list the dataset's feature names, given the dataset's name and the names of some initial features.
feature_names_test(“google-quest-challenge.csv”, “gpt-4o-2024-08-06“)
Similarly to the memorization tests above, we depict the Levenshtein distance between the model response and the actual feature names in the dataset. We see that the LLM response is fully green, meaning that GPT-4o responded with the feature names as they are listed in the first row of the competition’s CSV file.5
Running the feature names test for all datasets, it turns out that GPT-4o knows the feature names for 14 out of 18 competitions. Here is another example

and, for contrast, an example where GPT-4o does not know the feature names

GPT-4o knows the feature values of MLE-bench datasets
As another measure of how much the LLM knows about a dataset, we ask the LLM to provide observations from the dataset. The prompt structure for this is one of my personal favourites.
User: Dataset Name: Iris. Feature Names: sepal_length, sepal_width, petal_length, petal_width, species
Assistant: sepal_length = 5.1, sepal_width = 3.5, petal_length = 1.4, petal_width = 0.2, species = Iris-setosa.
sample(“OSIC Pulmonary Fibrosis Progression.csv”,
“gpt-4o-2024-08-06“,
temperature = 0.7,
num_queries = 5)
Here, we have parsed the LLM responses into a data frame. We see that we can use GPT-4o to sample observations from a dataset seen during pre-training, using only its parametric knowledge.6 The point here is that the values of some of the features in the dataset follow a particular format that cannot be correctly predicted without seeing the information about this particular dataset during pre-training (most importantly, the “Patient” feature).
We can formalize our approach in the feature values test. This test samples an observation from the LLM at temperature 0 (the “most likely” observation from the dataset, according to the LLM). Then, it looks for the dataset row that matches the LLM sample most closely.
feature_values_test(“OSIC Pulmonary Fibrosis Progression.csv”, “gpt-4o-2024-08-06“)
This test does not necessarily indicate contamination for all datasets because the feature values need to be sufficiently unique (GPT-4o can always provide realistic values for “Age” and “Percent”). For the depicted dataset, however, the format of the feature values is fairly unique, making it rather unlikely that GPT-4o could generate them without having seen observations from this dataset during pre-training (there are many plausible alternative formats for the values of the “Patient” feature, and GPT-4o just so happens to match the format of the data).
Running the feature values test for all 18 datasets, GPT-4o can generate realistic feature values for 12 out of 18 competitions.
GPT-4o recognises MLE-bench datasets
As our final measure of how much GPT-4o knows about the datasets in MLE-bench, we ask the LLM to provide the name of the dataset, given the initial rows of the CSV file.
dataset_name_test(“google-quest-challenge.csv”, “gpt-4o-2024-08-06“)It turns out that GPT-4o can recognise 10 out of 18 competitions from the first rows of their CSV files. This seems pretty important for contamination because it means that the LLM might be able to recognise the competition even if we apply obfuscation strategies—such as changing the competition description, as discussed in Section 4.2 of the MLE-bench paper.
We can make the dataset recognition task more challenging by providing the LLM not with the initial rows but a single random row from the dataset. When provided with a single random row from the CSV file as context, GPT-4o can still provide the name of 3 out of 18 MLE-bench competitions (the New York City Taxi Fare Prediction, Champs Scalar Coupling, and Spooky Author Identification).
What should we make of the contamination?
In this blog post, we have seen how the tabmemcheck package can be used to test GPT-4o for prior exposure with tabular datasets. We developed this package a while ago, and when OpenAI released MLE-bench, I was mostly curious to see how much the datasets in this benchmark would be contaminated in GPT-4o.
It turns out that there is little verbatim memorization of individual data points but quite significant contamination in terms of what the model knows about the different datasets. In particular, GPT-4o is quite capable of recognizing some competitions from their feature names or even random data points.
Estimating the impact of the observed contamination on the final performance evaluation in MLE-Bench is tricky. In our COLM paper, we compared the few-shot learning performance of GPT-4 on memorized and novel tabular datasets. We found that the degree of overfitting due to the memorization was about 6 percentage points (check the paper if you are wondering about the details of this). On MLE-bench, there is less memorization than what we observed for the dataset in our paper, and the performed task is much more indirect.7
My hunch is that the observed contamination does not severely impact the evaluation of GPT-4o on MLE-bench. However, it could plausibly lead to inflated performance evaluations on some of the datasets that GPT-4o seems to know very well. In my view, one should exclude datasets from the benchmark where GPT-4o can tell the name of the Kaggle competition given a few rows from the associated CSV files.
This blog post is based on work done at Microsoft Research with my amazing collaborators: Rich Caruana, Harsha Nori, Besmira Nushi, and Vanessa Rodrigues.

Citation
You can cite this blog post as
@article{bordt2024contamination,
title = "Data Contamination in MLE-bench: How to test language models for prior exposure with Kaggle competitions",
author = "Bordt, Sebastian",
journal = "sbordt.substack.com",
year = "2024",
url = "https://sbordt.substack.com/p/data-contamination-in-mle-bench"
}
In a sense, we instruct the chat model to mimic the behaviour of the base model. While this might not work for all chat models, it works very well for the models released by OpenAI and also for Llama 3.
Spooky Author Identification, RANZCR CLiP - Catheter and Line Position Challenge, New York City Taxi Fare Prediction, Plant Pathology 2020 - FGVC7, Tabular Playground Series - Dec 2021, Tabular Playground Series - May 2022, iWildCam 2019 - FGVC6, Google QUEST Q&A Labeling, Predicting Molecular Properties, Jigsaw Unintended Bias in Toxicity Classification, Toxic Comment Classification Challenge, Google Brain - Ventilator Pressure Prediction, Nomad2018 Predicting Transparent Conductors, PetFinder.my - Pawpularity Contest, chaii - Hindi and Tamil Question Answering, iMet Collection 2020 - FGVC7, SIIM-ISIC Melanoma Classification, OSIC Pulmonary Fibrosis Progression
Strictly speaking, this only means that we cannot extract any rows with our prompts.
Research generally finds that memorization only occurs if a text is repeated (many times) in the training data.
While this does not necessarily imply that GPT-4o saw the CSV file of the Google QUEST Q&A Labeling challenge during pre-training, it means that the model has seen enough information about the competition to be able to complete the task.
In their analysis of contamination, OpenAI does not consider the benchmark data but the existing (top) solutions to the Kaggle competitions. This is probably the most relevant type of contamination for this benchmark.